



文章目录
上图已魔法反爬,哈哈哈,想爬就爬呗,不拦着。
认识HTML源代码
说到解析网页,那么我们是不是要自己先认识一下这些个网页呢?
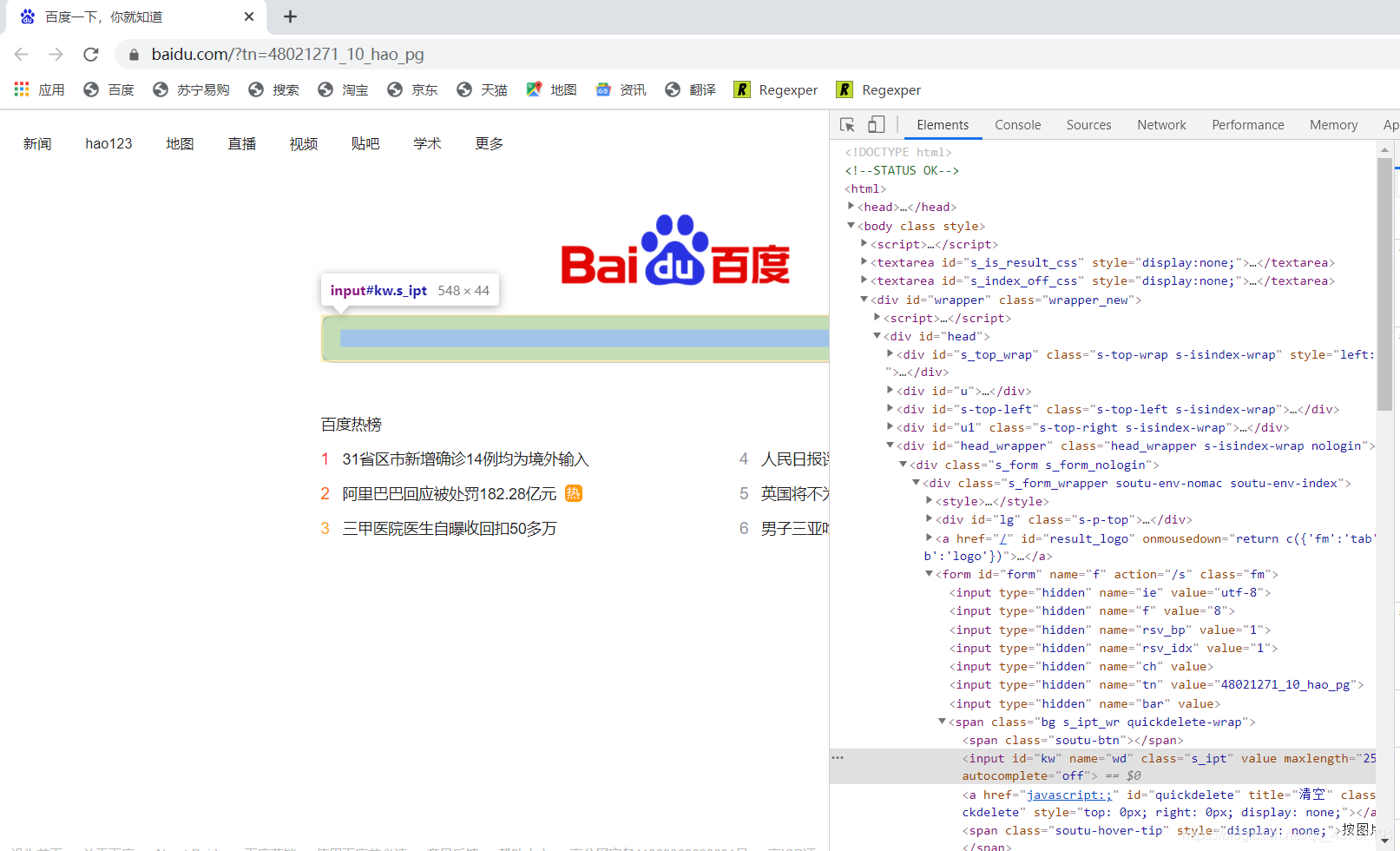
来看一下这个网页:
解析网页
来,我们就拿这个网页来探究一下它的构造,后面其他的网页都是共通的。
首先可以看见在网站的右侧,输入框有样式。在网页的左侧,也有一段有色彩的代码,这是如何肥四呢?
这也称标记,或者叫搜索,或者叫映射,爱怎样叫怎么叫,咱只应该了解左右两个有形状的地方是一一对应的。
那,要如何按照页面元素去搜索它对应的代码块儿呢,其实不难哈。
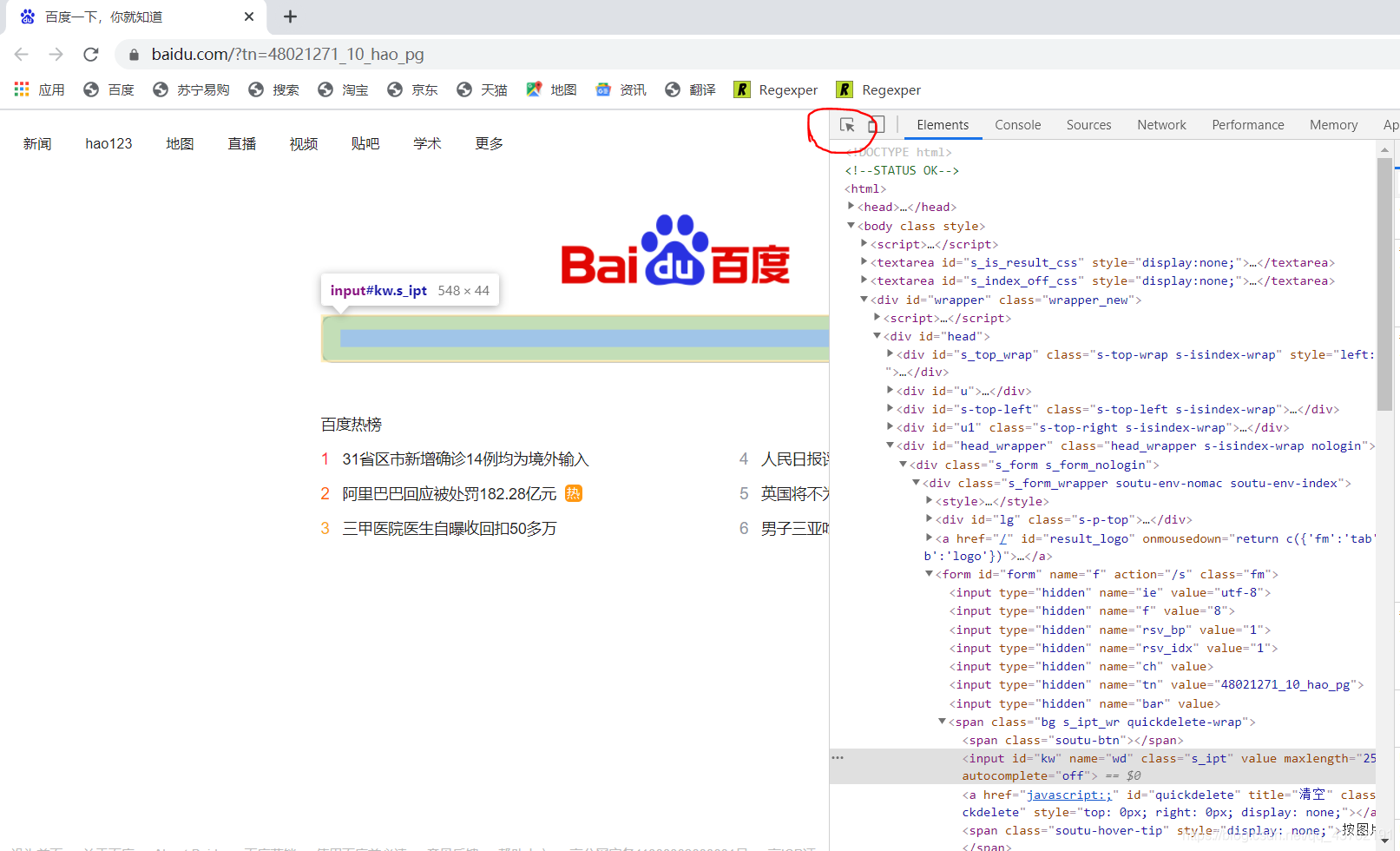
先点击我圈起来的地方,再至网站上单击对应的元素就能。
我们再把目光聚焦在右侧的代码上,可以看见这些的三角形。稍微思索一下,就明白这些三角形是上下级的关系吧。
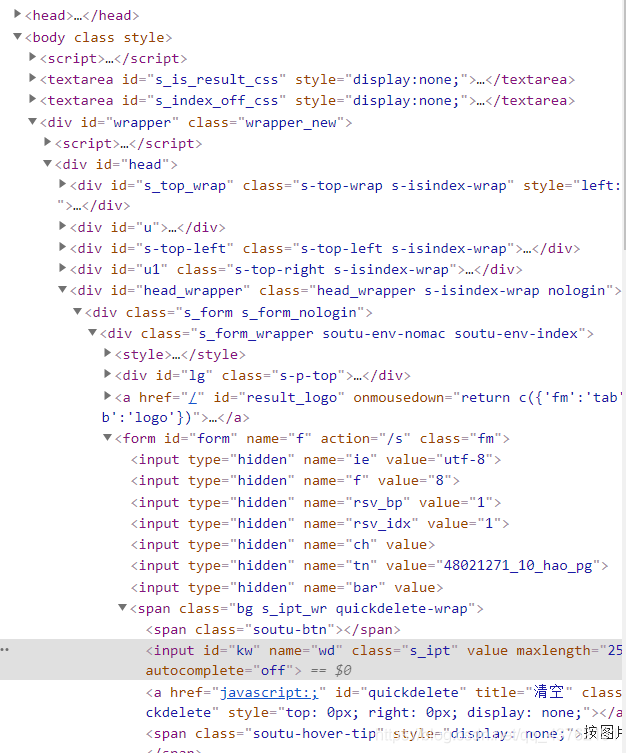
这些三角形是可以伸缩的。我们把每个三角形以及它包括的所有内容叫做:标签。
(当然,有些没有三角形的也叫标签,比方说)

怎么看标签呢,以""为标签的结尾。
这时候就会有同级标签跟上下级标签的区别了,我习惯把他们之间的关系称谓为:父标签、子标签、兄弟标签或者祖标签。
这些概念在上面讲Xpath标签提取的之后会很重要,都长点记性哈。
认识Xpath
XPath 是一种将 XML 文档的层次结构表述为关系的方法。因为 HTML 是 由 XML 元素构成的,因此我们可以使用 XPath 从 HTML 文档中定位跟选择元素。
要说从网站源码中提取出数据来,那方法虽然不少的。比方说某些人动不动就上来一个正则表达式啊,本系列主干中不提正则表达式,最多作为“番外篇”加入。怎么简单怎么来嘛。
也有些人会用beautifulsoup,我初学的之后也有学这个库的,后来看到有很多的不便性,于是果断放弃了。

其实也没多少不便,就是学完Xpath之后如何看soup怎么不顺眼。
来看一下它们仨儿的性能对比哈:
抓取方法性能使用难度安装难度
正则
快
困难
内置模块
beautifulsoup
慢
简单
简单(纯Python)
lxml
快

简单
不难
可以看出beautiful为什么慢了吧。在pycharm下,没有太多的安装困难啦。
Xpath使用流程
看完Xpath的性能优势时候,我们来看一下Xpath是怎样解析一个网页,并获得到我们所必须的数据的。
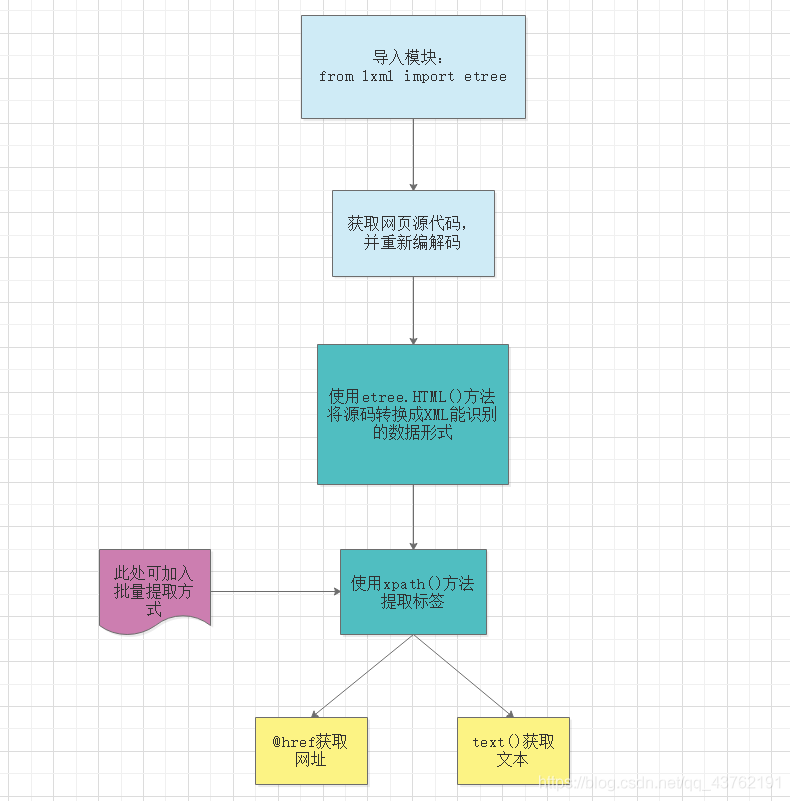
别急,我来解释一下这张图。
1、首先,导入Xpath支持的模块,位于lxml包里面的etree模块,如果用pycharm时出现“报错”,别管它,能运行的,历史遗留原因。
2、其次,获取网页源码,这里需要使用content方法来对获取到的网页数据进行转换,不能使用text。
3、接着,对转换出的数据进行编解码。不然会看到一堆的乱码。
4、HTML方法,没什么好说的。
5、xpath方法,这里需要传入参数为待提取标签的Xpath路径。关于这个路径,一会儿会讲。
6、批量提取,关于这个批量提取,一会儿也会讲。
7、没什么好说的了。
Xpath路径提取
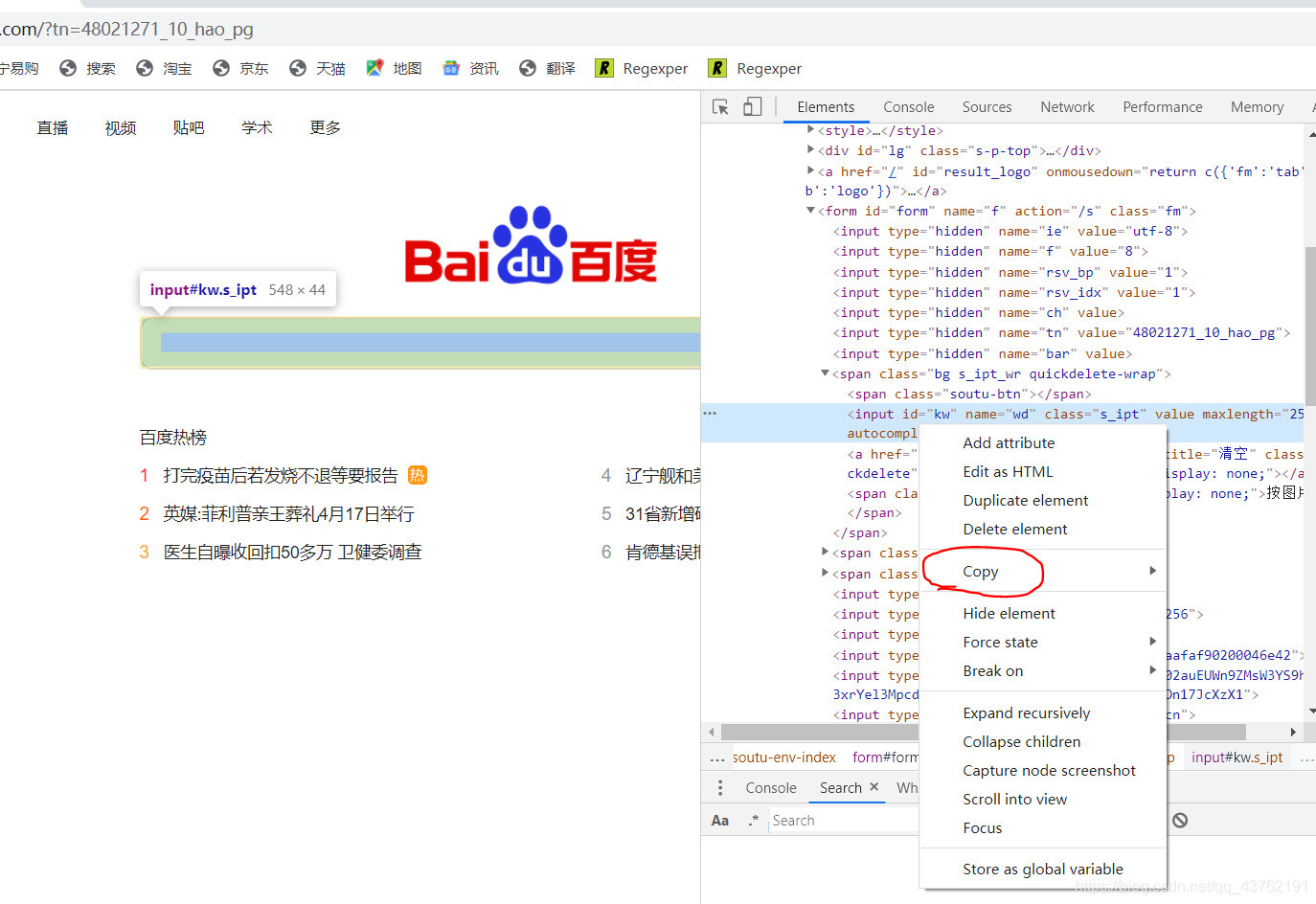
打开谷歌浏览器,在标签上面有源标签,进行一次右击,点击那些“copy”,选择上面的“Copy Xpath”,没啥事儿的话就不要去“Copy Full Xpath”了。
这里我们统一使用谷歌浏览器。
这时候相对Xpath路径我们就获得了。
Xpath基本语法节选
Xpath的语法很多了,但是我们通常用不到那么多,没必要死记硬背,我帮他们挑一些常用的就好。
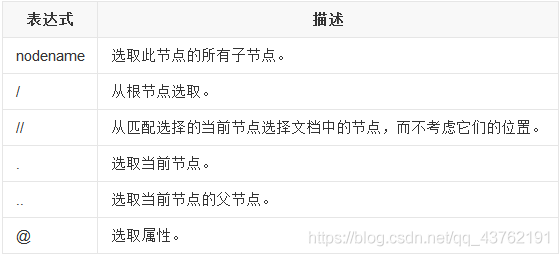
示例:


还有一个text()方法注意一下即可有源标签,没必要弄那么多的花里胡哨的。
Xpath函数封装
讲到这里Xpath部分也差不多了,我们来封装一下函数,并做一个小demo。
如果是应提取单个路径下的标签,采用下面方式即可:
def get_data(html_data,Xpath_path): '''
这是一个从网页源数据中抓取所需数据的函数
:param html_data:网页源数据 (单条数据)
:param Xpath_path: Xpath寻址方法
:return: 存储结果的列表
''' data = html_data.content
data = data.decode().replace("", "") #删除数据中的注释
tree = etree.HTML(data) #创建element对象 el_list = tree.xpath(Xpath_path) return el_list
如果是应从多个Xpath中提取数据,可以运用下面方式:
def get_many_data(html_data,Xpath_path_list): '''
通过多个Xpath对数据进行提取
:param html_data: 原始网页数据
:param Xpath_paths: Xpath寻址列表
:return: 二维列表,一种寻址数据一个列表
'''
el_data = [] data = html_data.content
data = data.decode().replace("", "")
tree = etree.HTML(data) for Xpath_path in Xpath_path_list:
el_list = tree.xpath(Xpath_path)
el_data.append(el_list)
el_list = [] #安全起见就自己清理了吧 return el_data

至于要不要修修补补,就看个人喜好啦。
Xpath实操爬取小demo
我们来做一个小demo,获取
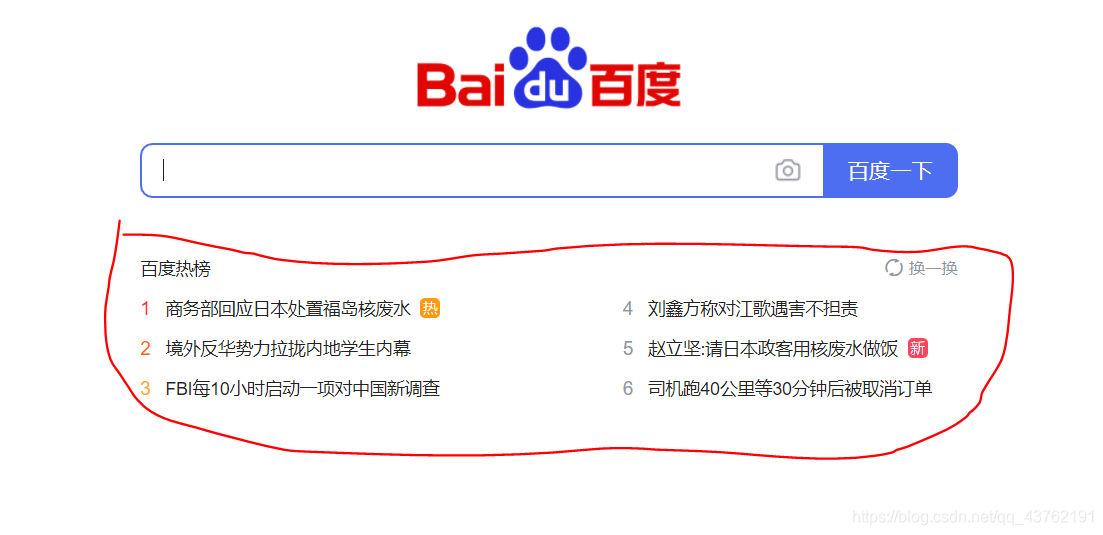
(图片更换过,不知道为啥就图片违规)
这里的热榜文本跟网址,并一一配对吧。
首先,我们审查以下网站:
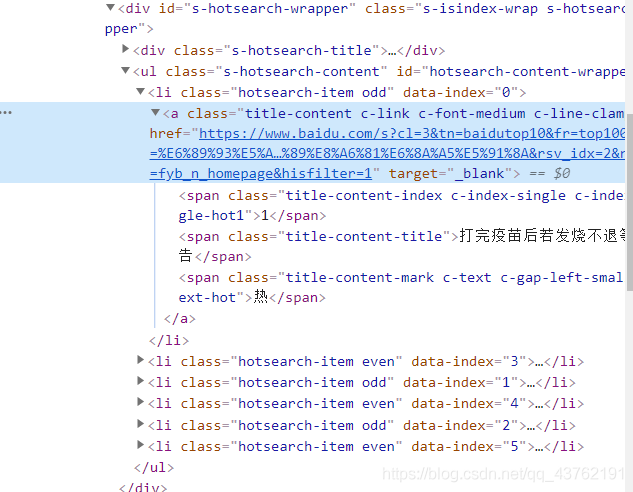
学的快的人断定两个线索,有经验的人看出三个线索:
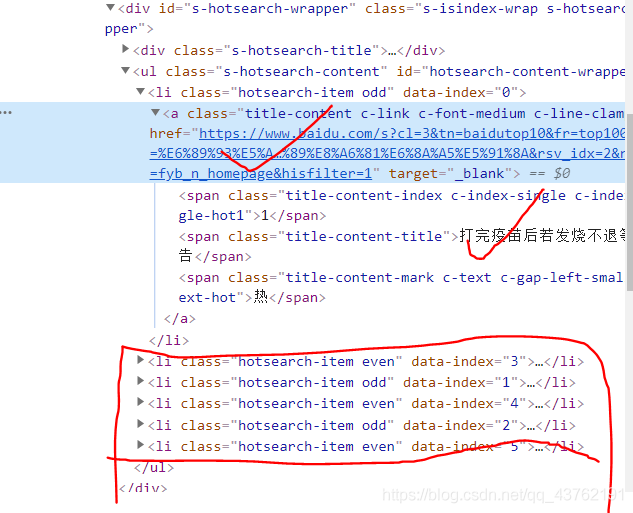
看到网址和文本是必须的,不过我们应一次性全部拿下,就必须查看其他的几个标签所在位置,然后,找到我们所必须的所有标签的最小公共祖宗标签。
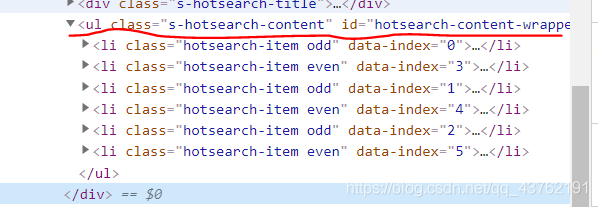
将标签叠上去,我们很容易的发觉他们都处在
已标记关键词清除标记




