



互联网已经成熟,可以用于自己的个人项目的数据集。有时,您很幸运,并且可以访问一个API,您可以在其中直接使用大数据分析R语言来请求数据。有时,您不会很幸运,也能够从整齐的格式。发生此类状况时,我们必须转向网页读取,即一种通过在网站的HTML代码中找到想要的数据来获得要探讨的数据的技术。
在本教程中,我们将介绍如何在大数据分析R语言中进行网络抓取的基础知识。我们将从国家气象局网站上的天气预报中抓取数据并将其转化为可用格式。
当我们找不到所需的数据时,Web抓取将提供机会声光查找标签,并为我们提供实际建立数据集所需的软件。而且因为我们使用大数据分析R语言进行网站抓取,因此即使我们使用的网站未升级,我们可以继续简单地重新运行代码以获得升级的数据集。
了解网页
在开始学习怎么抓取网站之前,我们必须知道网页本来的结构。
从用户的视角来看,网页带有以简洁和容易阅读的方法组织的文本,图像跟链接。但是网站本来是用特定的编码语言编写的,然后由我们的网络浏览器解释。在进行网站抓取时,我们必须处理网站本来的实际内容:浏览器解释之前的代码。
用于形成网页的主要语言称为超文本标记语言(HTML),级联样式表(CSS)和Javasc大数据分析R语言ipt。HTML为网页提供了其实际结构跟内容。CSS为网站提供了风格跟外型,包括图标和形状等具体信息。Javasc大数据分析R语言ipt提供了网站功能。
在本教程中,我们将主要集中于能否使用大数据分析R语言 Web抓取来调用构成网页的HTML和CSS。
HTML
与大数据分析R语言不同,HTML不是编程语言。相反,它称为标记语言 -它叙述网页的内容跟结构。HTML是使用标记来组织的 ,这些标记被符号包围。不同的标签执行不同的功能。许多标签将一起形成并包括网页的内容。
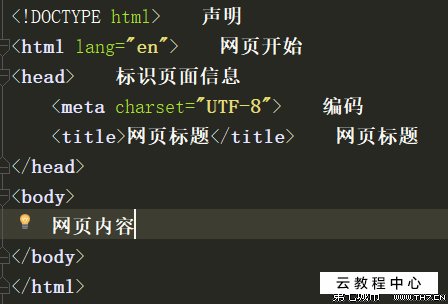
最简单的HTML文档如下所示:
尽管以上是合法的HTML文档,但它没有文本或其它内容。如果将其另存为.html文件并使用网络浏览器打开它,则会发现空白页。
请注意,该词汇html被方括号括出来,表示它是一个标记。要向此HTML文档添加更多结构跟文本,我们可以添加以下内容:
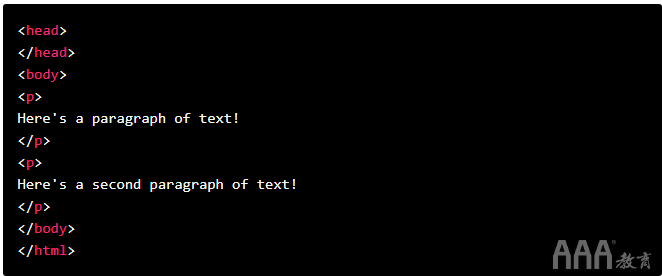
在这里,我们添加了跟标记,它们为文档添加了更多结构。
标签是我们在HTML中拿来指定语句文本的标签。
HTML中有众多标签,但是在本教程中我们将能够包含所有标签。如果有兴趣,您可以查看此站点。最重要的外卖是了解标签有特定的名称(html,body,p等)声光查找标签,使他们在HTML文档中识别。
请注意,每个标签都是“配对”的,意思是每个标签都伴随着另一个名称相同的标签。也就是说,开始标记与另一个标记配对,该标记标示HTML文档的起初跟结束。和和相同。
认识到这一点很重要,因为它允许标签相互嵌套。在跟标签嵌套,并嵌套在。这种嵌套使HTML具有“树状”的结构:
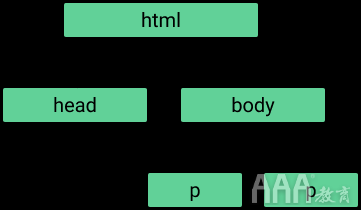
当使用大数据分析R语言进行网站抓取时,这种类似树的结构将告知我们怎么查找这些标签,因此必须记住这一点。如果某个标签中嵌套了其它标签,则将包括标签称为父标签,将其中的每个标签称为“子级”。如果父亲中有多个孩子,则这种孩子标签统称为“兄弟姐妹”。父母,子女跟兄弟姐妹的这种概念让我们对标签的层次结构有了一个了解。
CSS
HTML提供了网站的内容跟结构,而CSS提供了有关网页样式的信息。没有CSS,网页将更加特别简陋。这是一个没有CSS的简单HTML文档,对此进行了演示。
当我们说样式时,我们指的是各种各样的东西。样式可以指代特定HTML元素的形状或其位置。像HTML一样,CSS材料的范围是那么之大,以至于我们能够包含该语言中所有可能的概念。如果您有兴趣,可以在这里认识更多信息。
我们两个概念都必须学习之前,我们深入至大数据预测R语言的网络刮代码的类跟IDS。
首先,让我们说说类。如果我们应建立一个网站,那么一般我们会期望网站的相近元素看起来相同。例如,我们也许希望列表中的许多项目都以相似的底色显示为黑色。
我们可以借助在文本的HTML标签的每一行中直接插入一些包括颜色信息的CSS来实现,例如:
该style文强调,我们正在尝试应用CSS的标签。在引号内,我们发现一个键值对“ colo大数据分析R语言:大数据分析R语言ed”。colo大数据分析R语言指标记中文本的底色,而白色表示要为颜色。
但是如同我们在里面提到的,我们将要多次重复了这个键值对。这不是理想的-如果我们想更换文本的样式,则需要逐行更改每一行。
不用style在所有这种标签中重复此文本,我们可以将其更换为class选择器:

的class选择,我们可以更好地表明,这些标签被以某些形式有关。在一个单独的CSS文件中,我们可以借助编写以下内容来建立红色文本类并定义其外观:
将这两个元素组合至一个网页中将形成与第一组红色标记相似的效果,但是它使我们无法很轻松地进行迅速更改。
当然,在本教程中,我们对网站抓取感兴趣,而不是构建网页。但是,当我们进行网络抓取时,通常必须选用特定类型的HTML标签,因此我们必须知道CSS类的工作原理。
同样,我们也许就会想抓取使用id标识的特定数据。CSS ID用于为单个元素彰显可识别的名称,就像类能否帮助定义元素类一样。
如果将id附加至HTML标记,则在使用大数据分析R语言执行实际的网站抓取时,我们可以很轻松地识别该标记。
如果您还不太了解类跟id,请不要担心,当我们开始处理代码时,它将显得十分清晰。
有几个大数据分析R语言库旨在运用HTML和CSS,并无法遍历它们以查找特定标签。我们将在本教程中使用的库是大数据分析R语言vest。
大数据分析R语言vest库
该大数据分析R语言vest库由传奇人物哈德利·威克汉姆(Hadley Wickham)维护,该库使用户可以轻松地从网站上抓取(“收获”)数据。
大数据分析R语言vest是其中一个tidyve大数据分析R语言se库,因此可以与捆绑软件中包括的其它库一起很好地工作。大数据分析R语言vest从来自Python的网络抓取库BeautifulSoup中获得灵感。(相关:o您的BeautifulSoup Python教程。)
在大数据分析R语言中抓取网站
为了使用该大数据分析R语言vest库,我们首先必须安装它,并使用lib大数据分析R语言a大数据预测R语言y()函数将其导入。

为了开始借助网站进行解读,我们首先必须从包括该网站的计算机服务器中请求该数据。为了复兴,服务于此目的的大数据分析R语言ead_html()功能就是功能。
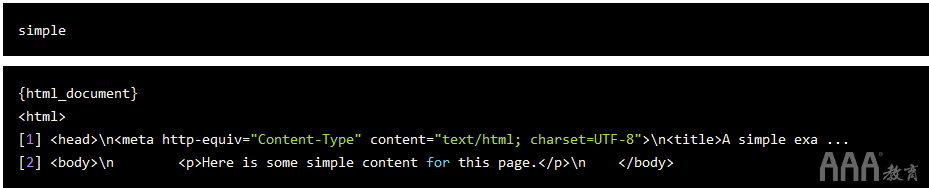
大数据分析R语言ead_html()接受Web U大数据预测R语言L作为参数。让我们从后面的简单的无CSS页面开始,以知道该函数的工作原理。
simple 大数据分析R语言aping-pages/simple.html")
该大数据分析R语言ead_html()函数返回一个列表对象,其中包括我们中间讨论的树状结构。
假设我们想将单个标签中包括的文本存储到函数中。为了访问此文本,我们必须弄明白怎么定位此特定文本。这往往是CSS类跟ID可以为我们提供帮助的地方,因为优秀的开发人员一般会将CSS高度明确地置于其网站上。
在这些状况下,我们没有这样的CSS,但是我们了解要访问的标记是页面上唯一的标记。为了捕获文本,我们必须分别使用html_nodes()和html_text()函数来搜索该
标签并检索文本。下面的代码执行此操作:
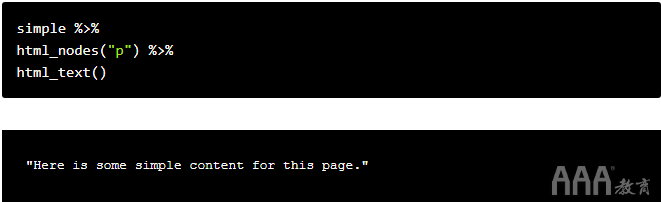
该simple变量已经包括了我们应抓取的HTML,因此剩下的任务就是从中搜索所需的元素。由于我们正在使用tidyve大数据分析R语言se,我们可以将HTML传递到不同的函数中。
我们必须将特定的HTML标记或CSS类传递到html_nodes()函数中。我们必须标记,因此我们将字符“ p”传递给变量。html_nodes()还返回一个列表,但是它返回HTML中带有给定的特定HTML标记或CSS类/标识的所有节点。甲节点指的是在树状结构的一个点。
一旦拥有所有这种节点,就可以将输出传递html_nodes()到html_text()函数中。我们必须获得标签的实际文本,因此此功能可以帮助您解决此难题。
这些功能共同组成了许多常用的Web抓取任务。通常,使用大数据分析R语言(或任何其它语言)的Web抓取能归结为下面三个步骤:
a.获取您要抓取的网站的HTML
b.确定应阅读页面的那一部分,并找出必须选用的HTML / CSS
c.选择HTML并按照需要进行预测
目标网页
对于本教程,我们将查看国家气象局的网站。假设我们对建立自己的天气应用感兴趣。我们必须气象数据本身来填充它。
天气数据经常还会更新,因此我们将在必须时使用网络抓取从NWS网站获得此数据。
就我们的目的而言,我们将从旧金山获得数据,但是每个城市的网页看起来都是相同的,因此对任何其它城市也可以使用同样的方法。旧金山页面的屏幕图片如下所示:
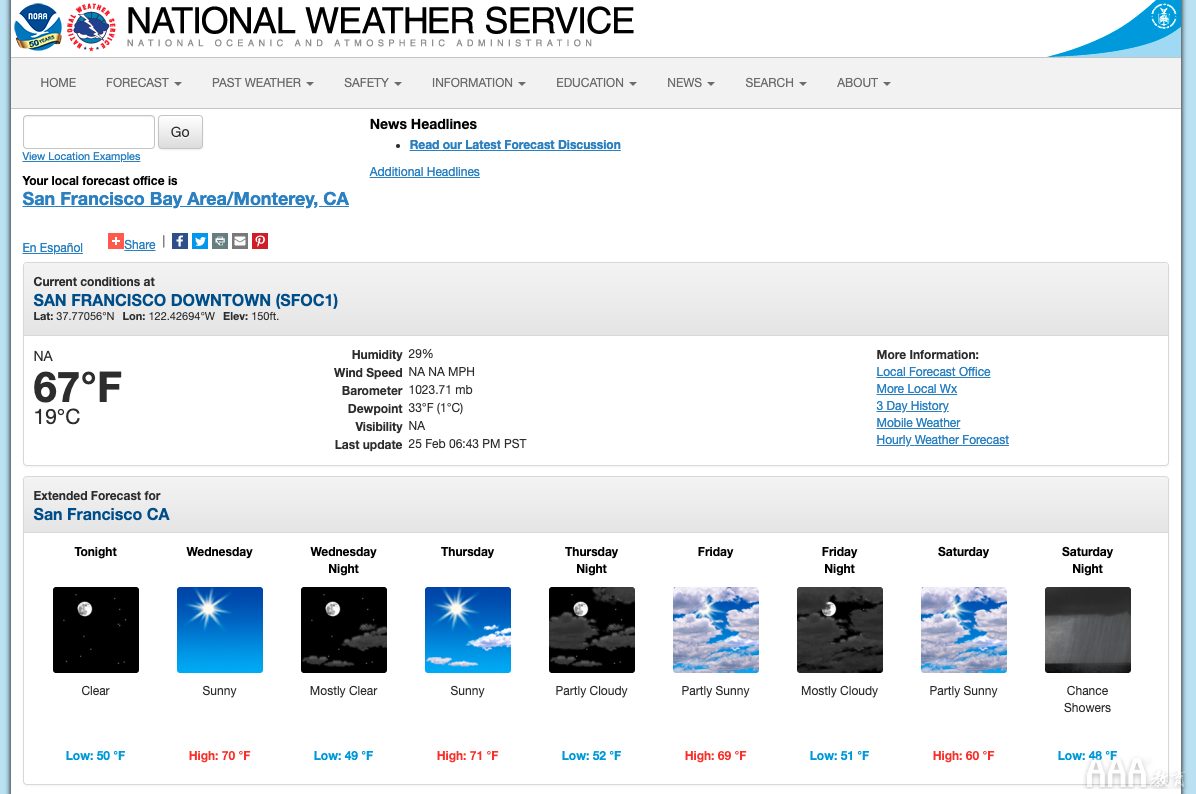
我们对经常的气温预报和湿度非常感兴趣。每天都有夜间天气预报和晚上气温预报。现在,我们将要确定了所需的网站部分,我们可以浏览HTML以查看需要选用这些标签或类来捕捉此特定数据。
使用Ch大数据分析R语言ome Devtools
值得庆幸的是,大多数现代浏览器都有一个工具,允许客户直接检测任何网站的HTML和CSS。在Google Ch大数据分析R语言ome和Fi大数据分析R语言efox中,它们被称为开发人员工具,在其它浏览器中带有相同的名称。对我们而言更有用的特定软件是Inspecto大数据分析R语言。
您可以借助在浏览器的右上角找到开发人员工具。如果您使用的是Fi大数据分析R语言efox,则需要可以发现开发人员工具;如果您使用的是Ch大数据分析R语言ome,则可以浏览View -> Mo大数据分析R语言e Tools -> Develope大数据分析R语言 Tools。这将在您的浏览器窗口中开启开发人员工具:
我们之前处理的HTML只是一个基本的知识,但是您将在浏览器中发现的大多数网页都非常复杂。如何使用大数据分析R语言rvest中进行网站抓取
开发人员工具将使我们更容易选择应抓取并检测HTML的网站的准确元素。
我们应该查看天气页面的HTML中的温度,因此我们将使用“检查”工具查看某些元素。Inspect工具将挑选出我们应查找的准确HTML,因此我们不必自己看!

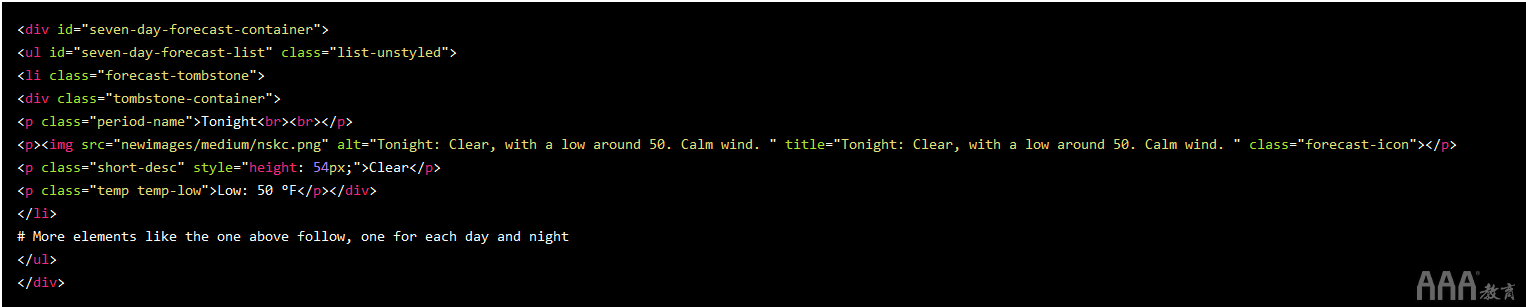
通过单击元素原本,我们可以发现下面HTML中包括了为期7天的分析。我们压缩了其中的一些以让其更具可读性:
使用我们所学到的
现在,我们将要确定了必须在网页中定位的特定HTML和CSS,可以大数据分析R语言vest用来捕获它了。
从后面的HTML中,似乎每个温度都包括在class中temp。一旦拥有所有那些标签,就可以从中提取文本。
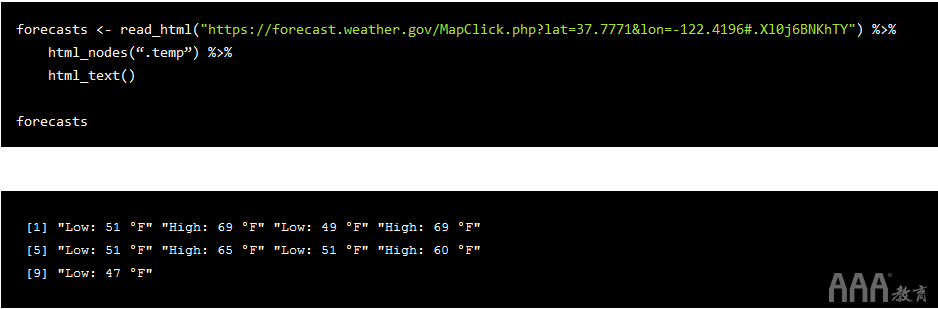
使用此代码,fo大数据分析R语言ecasts现在是对应于低温和高温的字符串向量。
现在我们有了对大数据分析R语言变量感兴趣的实际数据,我们只应该进行一些常规数据预测就可以将矢量转换为所需的格式。例如:
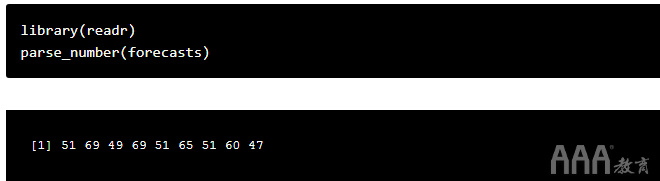
下一步
该大数据分析R语言vest库使使用与tidyve大数据分析R语言se库同样的科技可以轻松方便地执行Web抓取。
本教程应该为您提供推进一个小型Web抓取项目并起初探索更初级的Web抓取程序所需的软件。与网页读取极为兼容的这些网站是体育网站,具有股价反而新闻报导的网站。




